评估类别统计与混淆矩阵
课程内容
第 1 课,共 1 课
评估类别统计与混淆矩阵
在本快速指南中,您将:
- • 打开并显示一张国家农业影像计划(NAIP)航空正射影像、一个包含影像衍生训练数据的感兴趣区域(ROI),以及一张基于该正射影像生成的分类影像。
- • 查看基本和高级类别统计:包括像素的最小/最大/均值/标准差值、协方差、相关性、像素数量、每类百分比、直方图、特征向量和特征值。
- • 创建并查看混淆矩阵和精度指标。
示例数据
下载下面的示例数据。然后将 .zip 文件的内容解压缩到本地目录。
[NAIP_Classification.zip
2.3 MB
下载](assets/NAIP_Classification.zip)
打开并显示 NAIP 影像
- 从菜单栏选择 文件 > 打开。出现打开对话框。
- 转到保存示例数据的目录,并选择所有文件。
- 点击打开。出现选择基础 ROI 可视化图层对话框。
- 选择 NAIP_Subset_SanAntonio.dat 并点击 确定。影像被添加到图层管理器中,并在影像窗口中显示。第一个是分辨率为 60 厘米的 NAIP 真彩色影像。叠加在影像上的是五个类别的训练数据感兴趣区域(ROI):未分类(主要是阴影)、水体、建设用地、树木和地被物。

- 取消选中图层管理器中的 NAIP 影像,以查看同一区域的分类影像。一张由额外树(Extra Trees)机器学习分类器创建的影像。使用分类聚合和分类平滑工具清理了该影像。

供将来参考,机器学习分类工具在安装 ENVI 深度学习模块后可用。它们位于工具箱的机器学习文件夹中。本练习不需要 ENVI 深度学习或机器学习工具。

查看类别统计
- 在工具箱的搜索窗口中,输入 statistics。
- 双击搜索结果中出现的 类别统计 工具。出现分类输入文件对话框。
- 选择 NAIP_Classification_Residential.dat 并点击 确定。出现统计输入文件对话框。
- 选择 NAIP_Subset_SanAntonio.dat 并点击 确定。出现类别选择对话框。
- 使用 Ctrl 键多选 水体、建设用地、树木 和 地被物。在本练习中,我们将忽略未分类的类别。

- 点击 确定。出现计算统计参数对话框。
- 启用 直方图 和 协方差 选项。基本统计 和 输出到屏幕 选项默认已启用。
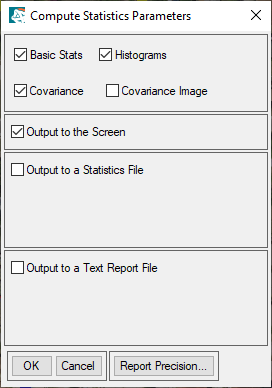
- 点击 确定。出现分类统计视图对话框。

查看基本统计
类别汇总 表显示了 NAIP 影像所有波段(红、绿、蓝、近红外)中每个类别的像素数量和百分比。
类别均值 图显示了 NAIP 影像所有波段中每个类别的平均亮度值。每个类别的均值也在各自的表格中报告。例如,水体表显示“水体”类别在红色波段的平均亮度值为 149.22。还为每个类别计算了其他基本统计,例如最小和最大亮度值以及标准偏差。

查看类别直方图
- 点击 选择绘图 下拉列表并选择 所有直方图 红。为每个类别绘制直方图,显示 NAIP 影像红色波段中的亮度值(“数据值”)和像素数量(“计数”)。

查看高级统计
每个类别都有一系列关于协方差、相关性、特征向量和特征值的表格。
- 滚动浏览“水体”类别的基本统计表之后的内容,并查看每个表格中的信息。

这些统计描述了相对于 NAIP 影像波段的类别变异性。一种更常见的方法是使用混淆矩阵来评估类别间的变异性和精度。接下来您将计算混淆矩阵和精度指标。
- 关闭分类统计视图对话框。
评估分类精度指标
- 在工具箱的搜索窗口中,输入 matrix。
- 双击搜索结果中出现的 使用地面真实 ROI 的混淆矩阵 工具。出现分类输入文件对话框。
- 选择 NAIP_Classification_Residential.dat 并点击 确定。出现匹配类别参数对话框。 匹配类别部分显示了地面真实(训练)ROI 的名称,而右侧显示了类别名称。ROI 和类别名称已经配对,因此您无需进行任何进一步操作。 但是,背景 ROI 需要与一个输出类别配对。ENVI 自动确定“未分类”是目标类别。
- 点击背景。“背景” ROI 被添加到地面真实 ROI字段。
- 点击未分类。“未分类”类别被添加到分类类别字段。

- 点击添加组合按钮。背景 <-> 未分类对 被添加到匹配类别列表中。
- 点击确定。出现混淆矩阵参数对话框。
- 取消选中像素选项。您将只评估百分比。
- 对于报告精度评估,保持默认的是选择。

- 点击确定。出现类别混淆矩阵对话框。报告包含一个混淆矩阵和精度指标。
混淆矩阵
混淆矩阵将影像中的真实类别(基于您提供的训练数据)与预测类别进行比较。这里呈现的混淆矩阵跨越多行,这使其难以解释。“未分类”行也重复了。

这是一个更易于理解的不同视图:

对角线上的值(为说明而高亮为黄色)是地面真实值与影像分类一致时的像素数量。在此示例中,有 11,600 个像素被正确分类为树木。
混淆矩阵还提供了关于分类器性能的更具体细节。让我们看看其中的一些指标。
Kappa 系数和总体精度

Kappa 系数是衡量分类器相对于随机数据的性能指标。这是一个过时的指标,对分类精度影响不大。全局或总体精度更值得关注。总体精度通过将正确分类的像素数相加,然后除以影像中地面真实像素的总数来计算。
总体精度仅提供了对分类器性能的初步总体估计。97.6% 的精度看起来很棒;但是,请记住,此评估并未考虑类别之间的细微差异。混淆矩阵其余部分的信息可以提供有关类别之间关系的更多细节。接下来我们将查看其中一些指标。
虚报误差
这些表示被预测属于某个类别但实际上不属于该类别的值所占的比例。它们提供了误报的度量。虚报误差显示在混淆矩阵的行中(不包括对角线上的值)。它们也以百分比和像素数的形式报告在类别混淆矩阵对话框的单独表格中。

漏报误差
这些表示实际上属于某个类别但被预测为其他类别的值所占的比例。它们是漏报的度量。漏报误差显示在混淆矩阵的列中(不包括主对角线上的值)。

生产者精度
这是给定类别中的值被正确分类的概率。

用户精度
这是被预测属于某个类别的值确实属于该类别的概率。该概率基于正确预测的值数量与被预测属于该类别的值总数之比。

有关解释这些指标的更多信息,请参阅 ENVI 帮助中的计算混淆矩阵(在新标签页中打开)主题。
本练习到此结束。
附加资源
- ENVI 机器学习教程:监督分类(在新标签页中打开) (PDF)
- 执行监督分类快速指南
您的意见对我们很重要,请花几分钟时间填写我们的快速指南反馈(在新标签页中打开)表单。
© 2024 NV5 Geospatial Solutions, Inc. 此信息不受《国际武器贸易条例》(ITAR)或《出口管理条例》(EAR)的控制。